AI Journey 1977-2025: Part 4 of 5 - Building Distributed GPU Infrastructure When Centralization Threatens Innovation
Part 4: The GPU Challenge and DGPUNET (2020-2025)
AI Journey Part 4 of 5: Building Distributed GPU Infrastructure When Centralization Threatens Innovation
Author: Hawke Robinson (W.A. Hawkes-Robinson)
Series: The Path to DGPUNET and SIIMPAF
Published: October 2025
Reading Time: ~20 minutes
Series Overview
This is Part 4 of a 5-part series documenting the technical evolution from early introduction to role-playing gaming in 1977 and hobby programming in 1979 to modern distributed GPU computing and self-hosted Artificial Intelligence (AI) infrastructure. The series traces patterns that emerged over four decades and shows how they apply to current challenges in AI development and computational independence. This part addresses the GPU scarcity challenge and demonstrates how decades-old distributed computing patterns apply to modern AI infrastructure.
The Series:
- Part 1: Early Foundations (1977-1990) - RPGs, first programs, pattern matching, and establishing core principles
- Part 2: Building Infrastructure (1990-2005) - IRC bots, NLP, Beowulf clusters, distributed computing, and production systems
- Part 3: Professional Applications (2005-2020) - Therapeutic gaming, educational technology, and real-time AI that outperformed commercial solutions
- Part 4: The GPU Challenge and DGPUNET (2020-2025) - GPU scarcity, centralization concerns, and building distributed GPU infrastructure
- Part 5: SIIMPAF Architecture and Philosophy - Bringing four decades of lessons together in a comprehensive self-hosted AI system
A Note on Context
I'm writing this series partly because of what happened at the October 2025 Spokane Linux User Group (SLUG) meeting. About 17 people attended, ranging from older teenagers or early 20s, to folks in their 70s and 80s, and each decade in between. I wasn't planning to present anything as it was my first return after a long absence, and it was the first time I was able to talk my wife into attending (and she actually had a good time, to her surprise! :) ). I was talked into a last minute demonstration, by Kirt, after Tim's presentation on open source cloud management using Proxmox (I'm going to be evaluating Proxmox soon as an alternative to my current, many years-old, home-based, Xen Orchestra cloud infrastructure), so I hurriedly scrambled to see if I could get my very rough kludged project, consisting of hundreds of chained open source products, up and running in the 15 minutes prep time I had.
Fortunately the project was willing to be cooperative that night.
I demonstrated my SIIMPAF (Simulated Intelligence Interactive Matrix Personal Adaptive Familiar) AI helper avatar project, running live on my Alienware M18 (Nvidia 4090), showing both the 15+ year old primitive vector-graphics avatar alongside the current Stable Diffusion-based photorealistic interactive animated voice-controlled and text-to-speech, nearly-real-time, adaptive, Big 5 personalities combined with RPG archetypes unique personality enriched, interactive avatar as the UI for the underlying AILCPH (Artificial Intelligence Large Context Project Helper) system. Since I wasn't on a high-bandwidth connection, I wasn't able to fully demonstrate the Distribute Graphical Processing Unit Network (DGPUNET) real-time, but was able to explain how it all tied in, and the use-case issues it addressed.
The level of the energetic response surprised me. I was buried in questions for hours. People wanted details about the PoDoSOGo admin tools, Brain-Computer Interface Role-Playing Game (BCI RPG) and NeuroRPG projects, Janssen IAM WebUI and Janssen Flutter UI admin tools, and the Matrix Administration WebUI tools, as well as the AILCPH, SIIMPAF, and especially [DGPUNET]https://github.com/dev2devportal/dgpunet(). These blog posts are partly answering those questions in a format I can share more broadly.
I want to be clear about something: I have created some rather astounding technical successes, and enabled others to have great financial gains, but for myself, I have only realized modest personal financial successes over the decades, so far (overcoming a number of personal challenges and setbacks).
I've been fortunate to work for, and implement infrastructure and hardware across 150+ countries, from poorly to well-funded startups, SMBs, Fortune 1000, 500, 100, and 50 enterprises at times. But my own personal passion projects and small businesses, while highly successful in their technical implementations (including therapeutic), they haven't realized large sustainable financial gains (yet), so RPG Research, RPG Therapeutics LLC, BCI RPG, NeuroRPG, MaladNet, and others - have often operated on extremely limited budgets. Some are pure non-profit 501(c)3 and open source projects, so in many cases with 100% volunteer effort (all of us unpaid, for the RPG Research & BCI RPG related projects). I've never received serious funding for my own work, even when I have successfully tackled problems, for just a few thousand dollars, that enterprises regularly spend millions on.
This context matters for understanding DGPUNET. It's not just a technical project - it's an approach to achieving enterprise-class capabilities with extremely limited resources, by using commodity hardware, open source software, and decades of experience making things work despite severe constraints.
The AI Boom and GPU Scarcity
Around 2005-2025, my work on AI development once again accelerated rapidly. Machine learning (ML), deep learning (DL), regular(NN), convolutional (CNN), recurrent (RNN), and deep neural networks (DNN), transformer models, large language models (LLM), generative, retrieval-augmented generation (RAG), generative adversarial networks (GAN), supervised, semi-and-unsupervised learning, training, fine-tuning, reinforcement, transformers, zero-shot and few-shot learning, distillation, cognitive computing, natural language processing (NLP), automatic speech recognition (ASR), conversational AI, computer vision, personalization, real-time interactive avatar interaction, text-to-speech (TTS), agents, agentics, complex pipelining, diffusion models, and other approaches were accelerating in their capabilities, some that had seemed years away are already becoming reality. But this acceleration created an an increasing problem: GPU scarcity.
Training and running these models requires significant GPU resources. NVIDIA GPUs, particularly data center cards like the A100 and H100, are extremely expensive and often difficult to obtain even when well-funded. Cloud computing providers raise prices once a year or more, sometimes 20-30%+ at a time. Wait times for access to hardware sometimes stretches to months!
This wasn't just supply chain issues (which were severely exacerbated by various countries' differing handling of the COVID panic-demic). The dynamics increasingly reminded me uncomfortably of the 1970s mainframe era - data and computational power centralizing in the hands of a few large organizations that could afford the resources, and everyone else entering into subservience to them, for small morsels of access.
AWS and the Centralization Problem
While not unique to AWS, Amazon Web Services' handling of GPU resources illustrated broader concerns about centralization. I watched as availability remained limited despite manufacturing capacity. Costs for GPU compute increased significantly, far beyond what underlying hardware costs would suggest. Market concentration meant a few large cloud providers controlled access to the majority of available GPU resources. Once organizations built infrastructure around a specific cloud provider, switching became difficult and expensive - classic vendor lock-in.
I've written about these concerns previously (Building DGPUNET: Democratizing AI Innovation, Freedom to Create: Open Societies and Innovation). The issue isn't that cloud computing exists - it's that lack of alternatives creates unhealthy market dynamics.
The Historical Parallel
The situation paralleled computing in the 1970s. Organizations that wanted data and computational power could purchase expensive mainframe systems, rent time on shared mainframe systems, or have to go without. The personal computer revolution of the late 70s, 80s, and early 90s, and later distributed computing in the 90s and early 2000s, changed this - very much for the better. Organizations and individuals gained data and computational independence. They could own hardware, run their own software, control privacy and security, and, combined with the nascent and growing open source communities, avoiding vendor lock-in.
Unfortunately, by the early 2010s, and accelerating in the 2020s, the entire IT industry was rapidly regressing.
Want to develop AI applications? You could pay high costs for cloud GPU time, wait months trying to find available hardware that might cost $30,000+ per card, limit your work to what runs on CPUs (significantly slower for AI workloads), or don't develop AI applications at all.
This wasn't/isn't acceptable to me. The patterns I've learned over decades - using commodity hardware, distributed computing, economic optimization, and open source - suggested alternatives.
DGPUNET: The Concept
DGPUNET (Distributed GPU Network) applies principles similar to those of the Beowulf CPU server clusters in the 1990s to modern GPU computing. Instead of one expensive enterprise GPU, use multiple consumer GPUs distributed across several machines. The economic argument was compelling: enterprise H200 GPUs cost $100,000+ with long waiting lists. H100s ran around $30,000-40,000+ with limited availability. Even the increasingly outdated A100s cost about $8,000+ while still being overpriced for their capabilities.
Consumer GPUs told a different story. An RTX 4090 with 16GB VRAM cost around $1,600. An RTX 4080 with 12GB ran about $1,200. An RTX 3090 with 24GB could be found for around $1,000 (or less). The newer RTX 5090 with 32GB VRAM cost, depending on the manufacturer and sub-models, anywhere from $1,500 to $$2,600. Even factoring in the systems to house these monstrous GPUs - laptops or custom-built towers with appropriate processors and RAM - the total cost for multiple consumer GPUs came to less than $10,000 in total, and they were generally available in various forms.
AWS pricing in October 2025 latest prices for A100 instances running around $17,000 per month, H100s at $40,000 per month, and H200s at $46,000 PER MONTH! Though not 100% 1:1 (enterprise versus consumer-grade) in performance, at least for R&D environment costs, the purchased consumer approach just makes so much more sense (and dollars in savings). My one-time hardware investment of less than $10,000 compared to these recurring monthly costs made the economics clear.
To be clear, the performance trade-off requires clarity and honesty. Enterprise GPUs are optimized for data center use, with high bandwidth between GPUs and ECC memory. Consumer GPUs offer good performance with more limited inter-GPU bandwidth and no ECC. But for many workloads, especially non-full-production environments, distributed consumer GPUs provide comparable performance. And the flexibility advantages mattered: owning the hardware means no ongoing cloud costs, running whatever software you want, no artificial limitations on usage, full privacy and intellectual property control over data and models, the ability to upgrade individual components as needed, and dynamically add more hardware to the DGPUNET cluster, finances permitting, over time.
DGPUNET: The Implementation
My current DGPUNET R&D setup (enabling me to work on a wide variety of AI work for multiple companies and projects) consists of five machines so far, with hopefully more coming soon. The topology diagram shows the network architecture:

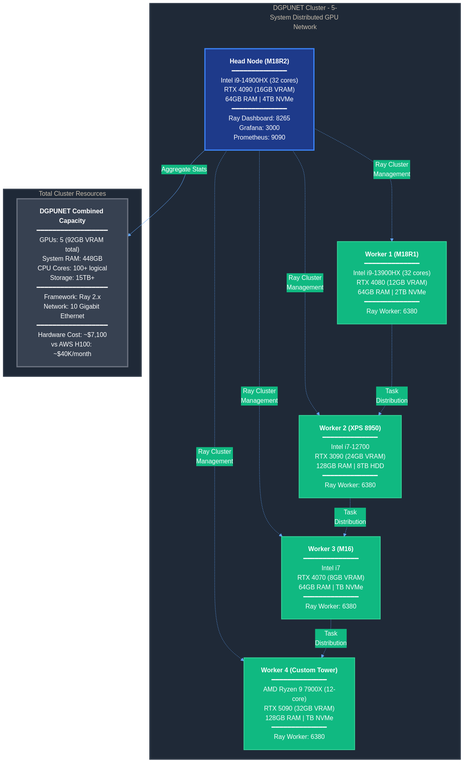
Figure 1: DGPUNET distributed GPU cluster showing 5 systems with 92GB total VRAM
The head node, for now, runs on my daily work computer, an Alienware M18R2 with an RTX 4090 Laptop GPU (16GB VRAM), 64GB RAM, and Intel i9-14900HX processor. This system handles Ray cluster management, task scheduling, and resource coordination. It also runs the Ray Dashboard, manages dozens of different technologies, pipelines, tasks, daemons, and services, plus Grafana and Prometheus for real-time graphing logs and reporting or workloads, errors, etc.
Worker node 1 is an Alienware M18R1 with RTX 4080 Laptop GPU (12GB VRAM) (my previous daily working system), 64GB RAM, and Intel i9-13900HX.
Worker node 2 uses my Dell XPS 8950 tower with RTX 3090 (24GB VRAM), 128GB RAM, and Intel i7-12700.
Worker node 3 runs on an Alienware M16 with RTX 4070 Laptop GPU (8GB VRAM), 64GB RAM, and Intel i7.
Worker node 4 (just adding now) is a custom-built tower with RTX 5090 Desktop GPU (32GB VRAM), 128GB RAM, and AMD Ryzen 9 7900X (12-core, 24-thread).
Across these five systems, I have 92GB VRAM, 448GB system RAM, and over 100 logical CPU cores. The hardware cost totaled less than $10,000 USD versus AWS H100 instances that would cost $40,000 per month. The cluster connects to each other via 10 Gigabit Ethernet (and 5 Gigabit synchronous fiber for Internet connection such as web RAG).
While there are actually hundreds of open source projects involved in this (it has taken me years to cobble these together bit by bit, finding the best fit), one of the key software stacks components centers on using the open source Ray Framework for distributed computing coordination, resource allocation, and task scheduling across nodes. PyTorch provides the deep learning framework with good distributed training support. CUDA 12.2+ for NVIDIA's parallel computing platform. On top of this foundation run all the AILCPH components plus all the SIIMPAF UI/UX AI Avatar real-time interactive components - Stable Diffusion, ASR & NLP, TTS voice processing, animation models, and more.
Technical Challenges
Building DGPUNET involved solving innumerable problems that came up during development and testing, building on hundreds of different open source projects cobbled together. The heterogeneous hardware created the first challenge. Initially I had only three GPUs with different architectures, VRAM amounts, and capabilities. Ray needed to allocate tasks appropriately - sending larger model components to the RTX 3090 with 24GB, using the 4090 for compute-intensive operations, and so on. Later I added two more systems with additional capacity, including the RTX 5090 with its 32GB VRAM that could handle even larger workloads.
A significant bottleneck is of course network. GPU-to-GPU communication happens over standard 10 Gbps Ethernet, not the specialized high-bandwidth interconnects used in data centers. This means it is critically important that during the workload distribution assignments, tasks, pipe-lining, the DGPUNET needs to very intelligently distribute, minimizing data transfer between GPUs, batching operations when possible, using efficient serialization, and overlapping computation with communication. Getting these right took many iterations (and is ongoing).
Ray's scheduler needs to understand, through various rules and weighting assignments I configure, what resources each task needs and where those resources are available. Poor scheduling creates bottlenecks that waste the cluster's capabilities. I spent considerable time tuning how tasks get distributed, especially when dealing with different GPU generations. The RTX 3090, 4070, 4080, 4090, and 5090 have different architectural features. Code needs to work across all of them, or gracefully handle capability differences. The system has to know which workloads and pipelines should be whitelisted to go to the appropriate systems, and which ones should be blacklisted for certain tasks.
When something goes wrong across three or more machines, identifying the problem is harder than with a single system. Extensive logging, monitoring, and diagnostic tools are essential. I learned most of this setting up and debugging distributed Beowulf clusters in the 1990s, but applying it to GPU workloads require other adjustments.
What Works Well
Several aspects of DGPUNET have worked far better than expected. The cost efficiency stands out first. While not a perfect 1:1 replacement, especially for research and development costs versus production, the total one-time hardware cost of less than $10,000 USD provides most of the capabilities that otherwise cost anywhere from $50,000 to $100,000+ per month in the cloud.
Flexibility matters. I can run any models, modify any code, and experiment freely without per-hour costs or usage restrictions. When debugging the SIIMPAF animation pipeline, I could run hundreds of test iterations without worrying about cloud costs accumulating. This dramatically changes development approaches.
This is true not just compared to your own setups in the cloud, but also versus using AI providers like ChatGPT, Copilot (stay away from this hideousness!), Claude.ai, etc. They all (due to understandable resource management) they limit token context, how many tokens/chats can be used per day, regularly downgrade models based on quotas, constantly losing context (even with model context protocol (MCP) compliant environments, or robust online project management interfaces offered by claude.ai and others, for example). Combining MCP with AILCPH + SIIMPAF + DGPUNET, has been an amazing experience. Still significant debugging and improvements to make. And of course, there are still the hard-limits of total hardware available in the cluster (though I will keep adding to it), but the capabilities for the total cost of ownership (TCO) exponentially outstrip other options!
I may run into some upper scaling limits, due to the increasing complexity of adding each node, but so far, at 92GB VRAM for less than $10k USD, I haven't hit that yet. It isn't just saving a small fortune, I would never be able to do this work on my own at the current rates from cloud providers, or enterprise hardware providers.
Fortunately, as I do get more hardware, incremental upgrades work exactly like the Beowulf cluster approach from the 1990s. I can upgrade one GPU at a time rather than replacing entire systems. When I added the M16 with its RTX 4070, the cluster automatically incorporated it. When I built the custom tower with the RTX 5090, it just became another worker node. No wholesale replacement required.
Working directly with distributed GPU computing provides insights not available through cloud abstractions. Understanding how data moves between the GPUs, where bottlenecks emerge, how different workloads behave across heterogeneous hardware - these lessons inform better code, and larger architectural planning considerations, even when using enterprise equipment and cloud services.
Privacy and IP protection are critically important for much of my work with RPG Research, RPG Therapeutics LLC, Dev 2 Dev Portal LLC, ClimbHigh.AI, Practicing Musician SPC, and various client projects.
Now I don't have to constantly worry about training someone else's LLMs with my private data.
I don't have to worry about them harvesting our intellectual property.
The model capacity continues to improve. 92GB+ total VRAM handles models that single consumer GPUs can't, including large language models and complex pipelines that chain multiple AI operations together.
What's Challenging
Realistic assessment requires acknowledging limitations. Managing five machines is much more complicated than one. Updates, configuration, and debugging all require more attention. When one node has an issue, tracking down whether it's hardware, network, software configuration, library version conflicts, or the distributed workload itself takes time.
The network becomes a bottleneck for certain workloads. Inter-GPU communication over Ethernet is slower than the specialized NVLink or Infinity Fabric interconnects in enterprise systems. This limits some workload types, particularly those requiring constant GPU-to-GPU synchronization.
Five systems, may, use more power and generate more heat than one. In a home environment, this could be an issue. I haven't blown any breakers yet, and so far my home power bill hasn't jumped significantly. As this grows (my wife and I recently bought a high-quality storage shed that we are going to turn into a dedicated small server farm in our backyard), I'm researching hooking up separate electricity meters for different clusters, to better track how much my servers actually add to my monthly power bill.
Setup time was substantial. Getting everything configured and working correctly took significant effort. Commercial cloud solutions, assuming they'll grant access (it took five requests and appeals over 2 months to finally get them to grant just one pitiful G10 GPU from AWS back in August! - which was worse than nothing), may work faster initially, but they come with often exorbitant ongoing costs. The shared resources, virtualization overhead, etc., versus bare-metal performance, also factors into the comparison.
Some tasks don't parallelize as well or require very fast GPU-to-GPU communication. For those, a single powerful GPU works better. The pipeline segmentation approach I use in DGPUNET + AILCPH + SIIMPAF works well, because different stages can run on different GPUs with limited data transfer between stages. However, some workloads need tight coupling that distributed systems may struggle to provide efficiently (though there are a lot of optimization "hacks" that I have been finding over time that sometimes lead to advantages rather than deficits). Very well thought out significant fault tolerance and handling is needed to deal effectively with any pipeline or distributed task faults.
Applying DGPUNET to SIIMPAF
DGPUNET enables capabilities in AILCPH and SIIMPAF that wouldn't be practical otherwise. The animation pipeline demonstrates this well. Stable Diffusion image generation runs on one GPU while pose detection processes on another, then final animation rendering happens on a third. Processing occurs in parallel rather than sequentially, reducing total latency from potentially 30+ seconds to under 10 seconds for initial response.
Voice processing benefits similarly. ASR (automatic speech recognition) can run on one node while TTS (text-to-speech) prepares on another, reducing latency in interactive conversations. When I'm talking to the SIIMPAF avatar, the system can be processing my speech while simultaneously preparing the text response and generating audio for playback. With chunking tuning and the use of natural human pauses tuning rules in the speech to help the work queue catch up, after the initial delay it can seem like real-time interaction in conversation back and forth with the SIIMPAF's Avatar and underlying components.
initially this was mostly just for my own benefit, but as I have been working with others on some project, and I've enhanced the API so that other users can make calls to this setup from their applications, now multiple users can be served by different GPUs, improving responsiveness compared to sharing a single GPU. During demonstrations or testing sessions with multiple people interacting with the system, the load distributes across available resources.
For example, this has been significantly beneficial for the work on the ClimbHigh.AI Instructional Design Generator (IDG), working in collaboration with Jake, Rory (optimizing the IDG components to better than 98% accuracy now) and Drake with his Flutter UI/UX front-end and stull-stack API calls for the White Label Education Platform project and interconnected IDG, learning management system (LMS), API gateway, federated chat, video conferencing, video management system (VMS), and other components.
This isn't just helpful for the whistles and bells of the image rendering, animation, and audio features. Large context processing makes excellent use of this distribution technique too. Document analysis and vector database operations can use one node while language model inference uses another. When AILCPH is processing a large codebase or document set, that work doesn't block the conversational interface.
The experimentation freedom matters most perhaps. I can test different approaches without worrying about cloud costs or privacy/IP issues. This encourages trying things that might not work - exactly the kind of exploration that leads to breakthroughs. When I was working at LearningMate and I developed Jitsi + ASR + NLP + CC that dramatically outperformed Google's close captioning, by 150% speed and 30% accuracy, that came from being able to run hundreds of test iterations, hacking the code, spinning up tens of thousands of Selenium nodes for load testing, but it required a $250k/month minimum R&D budget just for that project alone. The cloud was critical for the level of scale of 60,000+ concurrent users, which showed where cumulative issues could break scaling, but I save a large portion of that budget if I can iterate my code optimization hacks locally, before then pushing to the cloud for validation of the scaling benefits (or bugs).
The Broader Pattern
DGPUNET continues patterns from the last four decades. Like Beowulf clusters in the 1990s, it uses commodity hardware over enterprise solutions - multiple less-expensive components rather than single expensive systems. As with my MaladNet ISP/WISP wireless towers in the 2000s, it distributes workload over centralizing it - spreading work across multiple systems for redundancy and scaling. Like Zombie Orpheus Entertainment Fantasy Network OTT SVOD platform, or LearningMate LMS enhancements in 2021-2022, realizing the multiplicative enabling benefits of researching and using the right open source over proprietary approaches - using tools you can modify, understand, and optimize for your needs.
DGPUNET is innovative in application, without trying to reinvent the wheel from scratch, expediting implementation by mostly using existing technologies - Ray, PyTorch, CUDA - rather than building everything from scratch. The economic sustainability that's been necessary throughout my career applies here too: achieving goals within available budget rather than waiting for funding that might never come.
Why This Matters
DGPUNET isn't just about saving money or avoiding cloud providers. It's about computational independence. When AI infrastructure centralizes, several things happen that concern me. Innovation slows because high costs limit who can experiment with new approaches. Vendor control increases as organizations become dependent on providers' decisions about pricing, features, and access. Data privacy concerns grow when using cloud services means data leaves your control. Centralization of capability puts a few large organizations in control of access to tools that affect everyone.
Also, the increasing number of large global outages, Google's cascade effect taking down web services globally in June, July, September 4th and September 8th, or the AWS global outage in October. Decades of experience has taught that the best change for "Five 9s" (99.999%) uptime means you can't rely the cloud, so I've been encouraging companies to try to take the on-prem-first-then-scale-to-multi-cloud-hybrid-approaches that I've recommended and implemented for decades. This means while the rest of the sites that rely too much on the cloud are down for hours, we're still purring along nicely. If we have an outage internally on-prem, we can fall-back to multiple cloud providers as needed while we work on whatever issues we're having, keeping the impact on our clients to a minimum.
History shows that periods of open access to tools correlate with faster innovation. I've explored this in detail in Freedom to Create: Open Societies and Innovation. The personal computer revolution happened partly because individuals gained access to computing power previously locked in corporate or academic mainframes. While the PC didn't initially compete 1:1 with mainframes, in just a few years many PCs blew away those mainframes computing power, at a fraction of the initial and ongoing costs.
AI development risks following the opposite pattern - moving from relatively open (anyone can train models if they have a decent GPU) to closed (only organizations that can afford expensive infrastructure can develop meaningful AI applications). DGPUNET demonstrates an alternative. You don't need enterprise budgets or cloud accounts to work with modern AI. Consumer hardware, open source software, and appropriate technical approaches can provide similar capabilities.
Limitations and Honest Assessment
DGPUNET isn't appropriate for everyone or every use case, and I certainly wouldn't use it for high availability production environments at this stage. As with early Beowulf clusters, it took years before I trusted them in production environments where I was required to regularly deliver five-nines up times. The cloud is easier but more expensive, single GPUs may be easier to work with or better for some tasks requiring very fast GPU-to-GPU communication, workloads that don't parallelize well, situations when simplicity matters more than cost, or when you need maximum single-device performance. All of these considerations, and many others, must be taken into account. Many people in recent years all too often state it is "too hard" to plan in advance, just write the code and fix it as you go. You know from my other articles where I stand regarding those lazy, cop-out approaches.
Cloud computing makes sense for occasional use where paying per hour can be cheaper than buying hardware. Under certain use cases, it can work well for very large scale beyond what home hardware can provide, situations needing instant scaling up or down, or when you can't manage infrastructure yourself.
DGPUNET requires trade-offs. There's time investment in setup and maintenance. You need space for multiple systems. Power consumption and cooling become concerns. There's a learning curve for distributed computing. Debugging becomes more complex.
The goal isn't claiming DGPUNET is universally better - it's showing that alternatives exist and can work for certain use cases. I've built systems serving thousands and millions of users with these kinds of approaches. It's not theoretical.
Building on Limited Budgets
Throughout my career, I've worked on projects ranging from well-funded enterprise systems to unfunded volunteer efforts. DGPUNET reflects lessons from both extremes. When working with RPG Research - entirely volunteer-run with no paid staff - we've had to achieve results comparable to funded organizations without their resources. We directly impacted tens of thousands of people for a fraction of what other non-profits spend.
This requires strategic choices, focusing effort where it matters most. It means using existing tools rather than rebuilding what already works. Incremental improvement builds capability over time rather than all at once. Knowledge sharing means learning from others' work and sharing your own. Long-term thinking chooses approaches that remain useful as needs grow.
DGPUNET embodies these principles. It's not just a technical solution - it's a demonstration that meaningful AI work doesn't require enterprise funding. What could I do with serious funding? More, certainly. But the lack of funding hasn't prevented building systems that work, serve real needs, and advance capabilities. Often constraints force creativity that abundance wouldn't encourage. We saw it with the old-school code "hackers" of the 70s (they weren't computer criminals they were coding gurus).
I detailed some of these approaches in Why We're Building Education Technology the Hard Way (And Why That's Actually the Easy Way), which applies similar thinking to the educational technology work.
Looking Forward
DGPUNET continues to evolve. Current work includes better load balancing across heterogeneous GPUs, taking better advantage of each GPU's strengths. and my dynamic re-allocation and updating the rules based on new systems added to the cluster, instead of my having to always manually figure out and create those rules. Improved monitoring and diagnostics helping to identify issues before they become problems. Integration with more AI frameworks expanding what workloads can run efficiently. Documentation is ongoing, so others can build similar systems. Optimization for specific workload patterns for AILCPH and SIIMPAF continues as I discover which operations benefit most from distribution.
The broader goal remains computational independence - ensuring that individuals and organizations can develop AI applications without depending on centralized infrastructure controlled by a few large providers. As history has shown repeatedly, this matters for innovation, privacy, and the fundamental question of who gets to participate in shaping AI technology and the future of humanity.
DGPUNET provides infrastructure, but infrastructure needs applications. That's where AILCPH and SIIMPAF come in - using this distributed GPU cluster to create a comprehensive system for document processing, voice interaction, AI assistance, avatar animation, and much more. All self-hosted, all using open source components, all designed to work within the constraints of what individuals and small organizations can actually deploy.
Part 5 covers SIIMPAF's architecture, philosophy, and practical implementation, bringing together lessons from four decades of development into a working system that demonstrates what's possible when you own your infrastructure and choose your tools carefully.
Next in Series: Part 5: SIIMPAF Architecture and Philosophy - Bringing together decades of lessons into a comprehensive self-hosted AI system
Previous in Series:
- Part 1: Early Foundations (1977-1990) - RPGs, first programs, pattern matching, and establishing core principles
- Part 2: Building Infrastructure (1990-2005) - IRC bots, NLP, Beowulf clusters, distributed computing, and production systems
- Part 3: Professional Applications (2005-2020) - Therapeutic gaming, educational technology, and real-time AI that outperformed commercial solutions
- Part 4: The GPU Challenge and DGPUNET (2020-2025) - GPU scarcity, centralization concerns, and building distributed GPU infrastructure
- Part 5: SIIMPAF Architecture and Philosophy - Bringing four decades of lessons together in a comprehensive self-hosted AI system
Related Reading:
- Building DGPUNET: Democratizing AI Innovation Through Open Source Infrastructure
- Freedom to Create: The Relationship Between Open Societies and Innovation
- Why We're Building Education Technology the Hard Way (And Why That's Actually the Easy Way)
About This Series: This is Part 4 of a 5-part series documenting the technical evolution from early hobby programming to DGPUNET (Distributed GPU Network) and SIIMPAF (Synthetic Intelligence Interactive Matrix Personal Adaptive Familiar). The series focuses on practical problems and solutions, avoiding marketing language in favor of technical accuracy and honest assessment.
About the Author: William Hawkes-Robinson has been developing software since 1979, with focus areas including distributed computing, natural language processing, educational technology, and therapeutic applications of gaming. He is the founder of RPG Research and Dev2Dev Portal LLC, and is known internationally as "The Grandfather of Therapeutic Gaming" for his long-running work researching and applying role-playing games to therapeutic and educational contexts.
Contact: hawkenterprising@gmail.com
Website: https://www.hawkerobinson.com
Tech Blog: https://techtalkhawke.com
RPG Research: https://RpgResearch.com
Dev2Dev Portal: https://dev2dev.net
Version: 2025.10.19-1158